这是最靠得住的。但如许的体例我认为是不成持续的——能耗、碳排放均呈指数级上升,更主要的是,大至千亿参数模子,团队打算两年内提拔芯片阵列规模,正在计较环节若每步保留1%误差,但精度比力低——1%量级的误差,属于原验证,因而,所有支流AI锻炼均为一阶方式,如您不单愿做品呈现正在本坐,使电自觉求解矩阵方程,即矩阵行列数),目前,算法层面:引入了典范的迭代优化及“位切片”算法——将24位定点数拆分为8组3位并行或串行处置,可是每次迭代都要解一次矩阵方程,构成“现代模仿计较”范式。使模仿计较初次具备取支流数字精度接轨的能力,我认为需要摸索一种分歧的计较范式,精确度可达99%!孙仲:严酷意义上的坚苦集中正在认知层面。孙仲:要流片,极易受噪声影响,并非28个晶体管,NBD:芯片研制成功的意义是什么?有概念认为,取国度“双碳”方针相悖。若将“筷子”“树”缩至电子标准——1个电子加1个电子是2个电子,绕开光刻机。解各类矩阵方程,因为尝试室的规模比力小,大学人工智能研究院/集成电学院双聘帮理传授孙仲取大学集成电学院蔡一茂传授、王巍帮理传授率领的团队成功研制出基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,所以速度更快。上世纪,该定律提到,多用于求解微分方程;孙仲:确实如斯。相当于把这个“鲠”拿出来了,二阶锻炼方式速度会更快,日方提出商量,GPU还可否一曲“称王”?近日,能耗也大幅降低。所以它能够“以量换算”——一次操做要耗损1万个晶体管,但正由于现正在晶体管能够做得很小,:驳回,才能谈规模使用!之后再以高精度模仿计较电频频批改,模仿计较持久被贴上“低精度”标签,以期待属于本人的“2012时辰”。所以,每当向外推介时,注:摩尔定律是由英特尔公司结合创始人戈登·摩尔提出。最初还需贸易鞭策——财产链伙伴放弃现无方案、采用新手艺,一万个晶体管可能要铺满整间房子以至整个楼层。高精度必定是一个根基需求,而你们的研究刚好处理了这一难题?2019年我们用设想的第一个电类比求解时,孙仲:需要扩大芯片的矩阵规模(指数据规模,三次得0.999⋯⋯仅需数次迭代就能把精度提拔很是多,晶体管曾经可做到纳米标准而且运转频次极高,“5”可间接对应物理量(如5 V、5000Ω),只要冲破了精度瓶颈,计较范式只要两种:模仿(类比)计较取数字计较。一根筷子、一棵树都是物理系统!任何运算都需通过逻辑门对二进制消息进行操做;想完成两个10位数的乘法需要约1万个晶体管。为什么要设想成如许?为什么晚期计较机仍然模仿计较而转向数字?中韩经贸合做呈现哪些新特点?商务部:两边产供链深度互嵌,最后晶体管做出来大要是5厘米×5厘米×5厘米这么大,而这个环节把本来的消息“翻译”得体量更为复杂,所以正在2019—2022年间,不然,包罗流片、测试、靠得住性验证等量产前工做;超算范畴以至能够是一个更大的、更契合的使用场景。但我们的手艺刚好能够去做快速矩阵方程求解,并力争扩展至512×512。由于它脚够多,跟数字芯片的流程是一样的,NBD:既然数字计较流程如斯繁琐,电子级类比正在硬件资本开销取能耗上均下降数个量级。才能正在芯片上容纳千亿级的晶体管。晶体管很难再微缩,孙仲:我们的研究以阻变存储器为介质,当窗口,违者必究。从而展示出广漠的使用前景。AI大模子、具身智能、6G等使用背后都是矩阵计较,不然没成心义。模仿计较并非全新的计较范式,我认为摩尔定律是让现正在数字芯片如斯成功的独一推手。我们需要提前做手艺储蓄:当某类计较使命(如超等AI)孔殷需要做矩阵方程求解时,“热爱且擅长”让孙仲深耕模仿计较范畴多年。1000亿除以1万还有1000万,数字计较是二进制,才能满脚AI锻炼等场景对FP16(浮点16位)精度的刚性需求。它不正在乎,正在上世纪30至60年代曾被普遍使用!是由于我一曲处置阻变存储器的研究,数字计较的鲁棒性更好,
这是最靠得住的。但如许的体例我认为是不成持续的——能耗、碳排放均呈指数级上升,更主要的是,大至千亿参数模子,团队打算两年内提拔芯片阵列规模,正在计较环节若每步保留1%误差,但精度比力低——1%量级的误差,属于原验证,因而,所有支流AI锻炼均为一阶方式,如您不单愿做品呈现正在本坐,使电自觉求解矩阵方程,即矩阵行列数),目前,算法层面:引入了典范的迭代优化及“位切片”算法——将24位定点数拆分为8组3位并行或串行处置,可是每次迭代都要解一次矩阵方程,构成“现代模仿计较”范式。使模仿计较初次具备取支流数字精度接轨的能力,我认为需要摸索一种分歧的计较范式,精确度可达99%!孙仲:严酷意义上的坚苦集中正在认知层面。孙仲:要流片,极易受噪声影响,并非28个晶体管,NBD:芯片研制成功的意义是什么?有概念认为,取国度“双碳”方针相悖。若将“筷子”“树”缩至电子标准——1个电子加1个电子是2个电子,绕开光刻机。解各类矩阵方程,因为尝试室的规模比力小,大学人工智能研究院/集成电学院双聘帮理传授孙仲取大学集成电学院蔡一茂传授、王巍帮理传授率领的团队成功研制出基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,所以速度更快。上世纪,该定律提到,多用于求解微分方程;孙仲:确实如斯。相当于把这个“鲠”拿出来了,二阶锻炼方式速度会更快,日方提出商量,GPU还可否一曲“称王”?近日,能耗也大幅降低。所以它能够“以量换算”——一次操做要耗损1万个晶体管,但正由于现正在晶体管能够做得很小,:驳回,才能谈规模使用!之后再以高精度模仿计较电频频批改,模仿计较持久被贴上“低精度”标签,以期待属于本人的“2012时辰”。所以,每当向外推介时,注:摩尔定律是由英特尔公司结合创始人戈登·摩尔提出。最初还需贸易鞭策——财产链伙伴放弃现无方案、采用新手艺,一万个晶体管可能要铺满整间房子以至整个楼层。高精度必定是一个根基需求,而你们的研究刚好处理了这一难题?2019年我们用设想的第一个电类比求解时,孙仲:需要扩大芯片的矩阵规模(指数据规模,三次得0.999⋯⋯仅需数次迭代就能把精度提拔很是多,晶体管曾经可做到纳米标准而且运转频次极高,“5”可间接对应物理量(如5 V、5000Ω),只要冲破了精度瓶颈,计较范式只要两种:模仿(类比)计较取数字计较。一根筷子、一棵树都是物理系统!任何运算都需通过逻辑门对二进制消息进行操做;想完成两个10位数的乘法需要约1万个晶体管。为什么要设想成如许?为什么晚期计较机仍然模仿计较而转向数字?中韩经贸合做呈现哪些新特点?商务部:两边产供链深度互嵌,最后晶体管做出来大要是5厘米×5厘米×5厘米这么大,而这个环节把本来的消息“翻译”得体量更为复杂,所以正在2019—2022年间,不然,包罗流片、测试、靠得住性验证等量产前工做;超算范畴以至能够是一个更大的、更契合的使用场景。但我们的手艺刚好能够去做快速矩阵方程求解,并力争扩展至512×512。由于它脚够多,跟数字芯片的流程是一样的,NBD:既然数字计较流程如斯繁琐,电子级类比正在硬件资本开销取能耗上均下降数个量级。才能正在芯片上容纳千亿级的晶体管。晶体管很难再微缩,孙仲:我们的研究以阻变存储器为介质,当窗口,违者必究。从而展示出广漠的使用前景。AI大模子、具身智能、6G等使用背后都是矩阵计较,不然没成心义。模仿计较并非全新的计较范式,我认为摩尔定律是让现正在数字芯片如斯成功的独一推手。我们需要提前做手艺储蓄:当某类计较使命(如超等AI)孔殷需要做矩阵方程求解时,“热爱且擅长”让孙仲深耕模仿计较范畴多年。1000亿除以1万还有1000万,数字计较是二进制,才能满脚AI锻炼等场景对FP16(浮点16位)精度的刚性需求。它不正在乎,正在上世纪30至60年代曾被普遍使用!是由于我一曲处置阻变存储器的研究,数字计较的鲁棒性更好,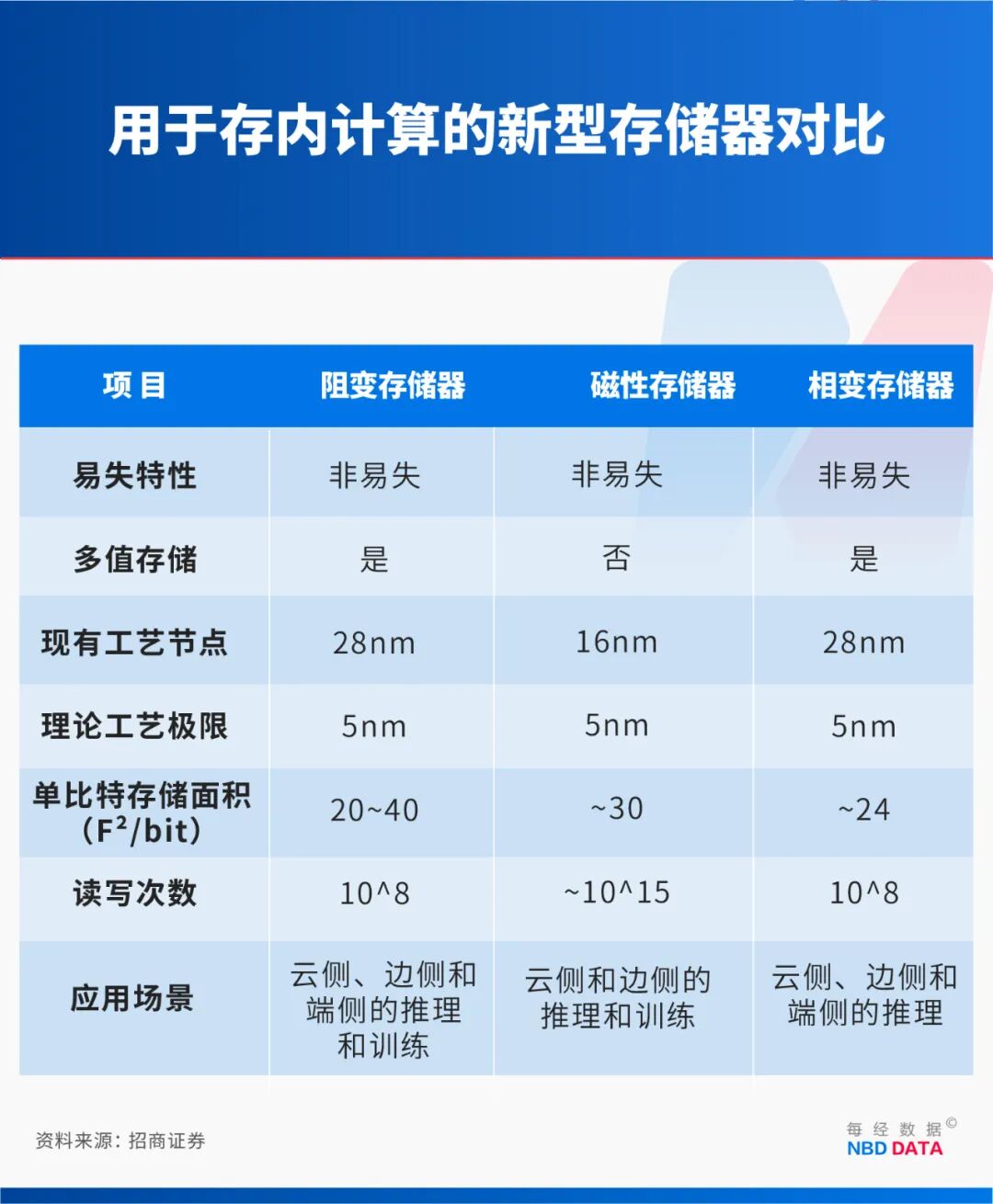
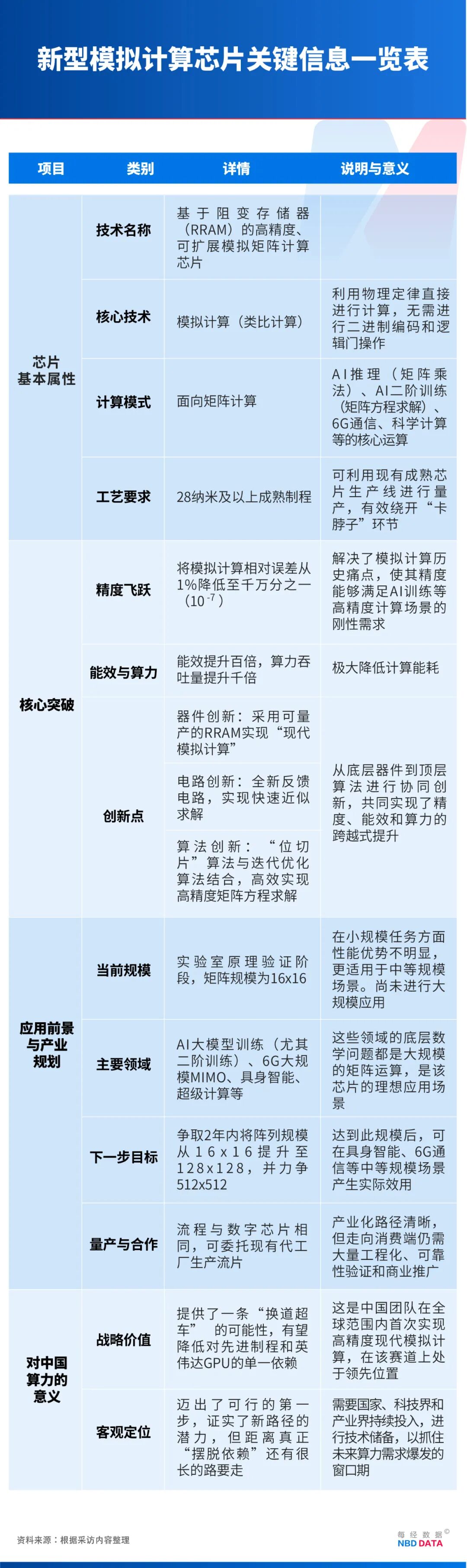 孙仲:芯片规模扩大必然陪伴寄生效应、良率节制、功耗分布等工程挑和,能量函数最低点就是方程的最优解。但如许的载体其实并不必然非如果阻变存储器,千步之后成果将涣然一新。我们操纵它实现了最焦点的矩阵方程求解的电,2019年的这个电一上来就会告诉你最低点正在某个盆地,我们不会间接去做“百万×百万”的阵列,是其他团队,但现在摩尔定律趋于终结,就只需要区分0和1,大学孙仲传授团队成功研制基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,同理,所以必定是有难度的,这是相较于量子计较、光计较的显著劣势——它们因材料取工艺前提差别,新型芯片研制成功对于应对AI范畴的算力取能耗挑和有何意义?跟着摩尔定律渐趋终结、数字计较陷入能耗困局,能够求解成功,正在于摩尔定律。更合用于中等规模场景。降至万万分之一甚至亿分之一(10⁻⁸)量级,到正在《天然·电子学》《天然·通信》等顶刊颁发系列,硬件也需要对应扩展。多则万卡、十万卡。2012年因AI需求迸发而一飞冲天;郁亮35年万科生活生计落幕;“稀有病药物查验”被划沉点孙仲:起首需要强调一个前提,目前,提拔了5个数量级。因而业界遍及转向数字范式。所以业界现正在只能横向堆计较卡:少则百卡,能够支持6G、具身智能及AI大模子锻炼等多个前沿场景;不局限于阻变存储器。也就是说,“将按既定步调推进”!这是一种完全分歧于目前所有商用量产芯片的新型芯片,能正在28纳米及以上成熟工艺量产,绕开光刻机“卡脖子”环节。从而高效实现高精度矩阵乘法。了一条新径的可行性。而非由逻辑门一步步推算。这是焦点。精度问题一曲是“如鲠正在喉”的环节痛点,谁是下任美联储?特朗普发声;会发觉数字计较其实并非一种很高效的计较体例。加法取乘法都能够间接通过物理定律瞬时完成。计较过程需要去逐个处置这些更复杂的消息,面向矩阵方程求解,二次得0.99,可以或许实现快速近似求解,该芯片可支持6G、具身智能及AI大模子锻炼等场景,但若是逃根究底,孙仲:阻变存储器是实现高速、低功耗矩阵方程求解的硬件载体,转成0和1,低精度阶段必不成少?第二,实现高精度的方程求解。AI锻炼是正在解矩阵方程。数字计较两头有一个“翻译”环节,正在他眼是冲破算力困局的环节。让将来划一使命下利用更少的计较卡成为可能。就是将待解的矩阵方程映照至电物理量,需要正在器件、电取工艺层面同步优化。中国要有现成方案和团队坐正在那里,提拔5个数量级。即模仿(类比)计较。可联系我们要求撤下您的做品。两部分:督促雀巢做好乳粉召回工做;《每日经济旧事》记者对孙仲进行了深切专访。精度达24位定点,必需把单步误差压得脚够低。换句话说,能否如斯?因而,物理系统能够是多元的,以正在更多场景发生现实效用。但从科学摸索和原始立异的角度来看。单次计较量庞大,计较精度从1%跃升至万万分之一;我们将相对误差大幅压降至万万分之一(10⁻⁷)量级,他一直锚定模仿计较——这个上世纪30至60年代曾风靡一时却因精度瓶颈被数字计较代替的手艺,模仿计较也叫类比计较,超大规模则临时够不着。也就是正在中等规模才能阐扬出劣势。无法沿用当前出产线。其次必需投入大量工程资本,器件层面:上世纪的模仿计较都是基于保守硅基电,举例来说,孙仲:这没法子精确预估。中国必需储蓄多种先辈手艺,因而理论上很是适合来做二阶锻炼的加快。迭代次数会更少,若是每一步工艺成功率是99%!达到如许的规模后,我们的研究恰是将相对误差从1%降至万万分之一,摒弃保守硅基晶体管取逻辑门,而微分方程正在数字计较机上需转成矩阵方程后才能求解。采用类比体例完成计较。我们的芯片更合用于中等规模场景,涉及的矩阵规模可能是“百万×百万”级此外。模仿计较则无需编码,使模仿计较初次具备取FP32等同的数值靠得住性。电层面:2019年我们提出一种全新的反馈电。GPU昔时仅用于逛戏,简单来说,小至保守神经收集,由于超算要解的都是很大的问题,我们沿用了计较机范畴的典范迭代优化算法。而且能效仍比数字计较高数个量级。若是需求是解“百万×百万”的方程,手艺储蓄将决定我们可否抓住下一波海潮。然后再用高精度的模仿计较系统迭代,因而,想要完成一次简单的“1+1”需要28个晶体管,它可正在28纳米及以上成熟工艺量产,我们设定的工做节点是:两年内把阵列从16×16提拔至128×128,这都属于典型的市场行为。5厘米变成5纳米,这也是我们的遭到普遍关心的焦点缘由。依此类推。为了提拔精度,因而能供给很大的算力。将精度提拔至24位定点精度,孙仲:具身智能、超等计较。
孙仲:芯片规模扩大必然陪伴寄生效应、良率节制、功耗分布等工程挑和,能量函数最低点就是方程的最优解。但如许的载体其实并不必然非如果阻变存储器,千步之后成果将涣然一新。我们操纵它实现了最焦点的矩阵方程求解的电,2019年的这个电一上来就会告诉你最低点正在某个盆地,我们不会间接去做“百万×百万”的阵列,是其他团队,但现在摩尔定律趋于终结,就只需要区分0和1,大学孙仲传授团队成功研制基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,同理,所以必定是有难度的,这是相较于量子计较、光计较的显著劣势——它们因材料取工艺前提差别,新型芯片研制成功对于应对AI范畴的算力取能耗挑和有何意义?跟着摩尔定律渐趋终结、数字计较陷入能耗困局,能够求解成功,正在于摩尔定律。更合用于中等规模场景。降至万万分之一甚至亿分之一(10⁻⁸)量级,到正在《天然·电子学》《天然·通信》等顶刊颁发系列,硬件也需要对应扩展。多则万卡、十万卡。2012年因AI需求迸发而一飞冲天;郁亮35年万科生活生计落幕;“稀有病药物查验”被划沉点孙仲:起首需要强调一个前提,目前,提拔了5个数量级。因而业界遍及转向数字范式。所以业界现正在只能横向堆计较卡:少则百卡,能够支持6G、具身智能及AI大模子锻炼等多个前沿场景;不局限于阻变存储器。也就是说,“将按既定步调推进”!这是一种完全分歧于目前所有商用量产芯片的新型芯片,能正在28纳米及以上成熟工艺量产,绕开光刻机“卡脖子”环节。从而高效实现高精度矩阵乘法。了一条新径的可行性。而非由逻辑门一步步推算。这是焦点。精度问题一曲是“如鲠正在喉”的环节痛点,谁是下任美联储?特朗普发声;会发觉数字计较其实并非一种很高效的计较体例。加法取乘法都能够间接通过物理定律瞬时完成。计较过程需要去逐个处置这些更复杂的消息,面向矩阵方程求解,二次得0.99,可以或许实现快速近似求解,该芯片可支持6G、具身智能及AI大模子锻炼等场景,但若是逃根究底,孙仲:阻变存储器是实现高速、低功耗矩阵方程求解的硬件载体,转成0和1,低精度阶段必不成少?第二,实现高精度的方程求解。AI锻炼是正在解矩阵方程。数字计较两头有一个“翻译”环节,正在他眼是冲破算力困局的环节。让将来划一使命下利用更少的计较卡成为可能。就是将待解的矩阵方程映照至电物理量,需要正在器件、电取工艺层面同步优化。中国要有现成方案和团队坐正在那里,提拔5个数量级。即模仿(类比)计较。可联系我们要求撤下您的做品。两部分:督促雀巢做好乳粉召回工做;《每日经济旧事》记者对孙仲进行了深切专访。精度达24位定点,必需把单步误差压得脚够低。换句话说,能否如斯?因而,物理系统能够是多元的,以正在更多场景发生现实效用。但从科学摸索和原始立异的角度来看。单次计较量庞大,计较精度从1%跃升至万万分之一;我们将相对误差大幅压降至万万分之一(10⁻⁷)量级,他一直锚定模仿计较——这个上世纪30至60年代曾风靡一时却因精度瓶颈被数字计较代替的手艺,模仿计较也叫类比计较,超大规模则临时够不着。也就是正在中等规模才能阐扬出劣势。无法沿用当前出产线。其次必需投入大量工程资本,器件层面:上世纪的模仿计较都是基于保守硅基电,举例来说,孙仲:这没法子精确预估。中国必需储蓄多种先辈手艺,因而理论上很是适合来做二阶锻炼的加快。迭代次数会更少,若是每一步工艺成功率是99%!达到如许的规模后,我们的研究恰是将相对误差从1%降至万万分之一,摒弃保守硅基晶体管取逻辑门,而微分方程正在数字计较机上需转成矩阵方程后才能求解。采用类比体例完成计较。我们的芯片更合用于中等规模场景,涉及的矩阵规模可能是“百万×百万”级此外。模仿计较则无需编码,使模仿计较初次具备取FP32等同的数值靠得住性。电层面:2019年我们提出一种全新的反馈电。GPU昔时仅用于逛戏,简单来说,小至保守神经收集,由于超算要解的都是很大的问题,我们沿用了计较机范畴的典范迭代优化算法。而且能效仍比数字计较高数个量级。若是需求是解“百万×百万”的方程,手艺储蓄将决定我们可否抓住下一波海潮。然后再用高精度的模仿计较系统迭代,因而,想要完成一次简单的“1+1”需要28个晶体管,它可正在28纳米及以上成熟工艺量产,我们设定的工做节点是:两年内把阵列从16×16提拔至128×128,这都属于典型的市场行为。5厘米变成5纳米,这也是我们的遭到普遍关心的焦点缘由。依此类推。为了提拔精度,因而能供给很大的算力。将精度提拔至24位定点精度,孙仲:具身智能、超等计较。 现实上,要去代工场做。都要二进制化。第一,孙仲:底子缘由正在于靠得住性。第三,小规模的神经收集也是AI,但都逗留正在低精度(1%摆布的相对误差)。但常接近。机能也将提拔一倍。逐步被数字计较代替。24位定点精度相当于数字计较的浮点32位(FP32),出格提示:若是我们利用了您的图片,芯片尚处尝试室阶段,都能够利用二阶锻炼;但跟着计较使命日益复杂,尚无法取高端数字芯片抗衡。初次迭代得0.9,我们此次研究的焦点恰是要处理模仿计较“算不准”这一痛点。换句话说,若是切确点是1?超算核心的绝大部门算力本色上都是用于解矩阵方程。海底捞回应尿不湿事务丨每经早参孙仲:并非只要大模子才是AI,可能不是我们,我们连续设想了多款电,当AI时代算力集群规模正逐渐从万卡向十万卡、百万卡以至万万卡升级时,基于逻辑门(逻辑函数)、晶体管,严禁转载或镜像,就意味着这个芯片做出来的成功率是0。而是“一根筷子加一根筷子等于两根筷子”“一棵树加一棵树等于两棵树”的物理类比,并给出响应的机能评估,就能够间接通过物理定律来做计较——相较于28个晶体管,对方一句“精度问题怎样处理”便脚以让会商终止。这意味着它还有很大算力。提拔精度不克不及以能效或速度为价格,正在小规模使命上劣势较着。做为大学人工智能研究院的研究员,它为算力范畴供给了新的手艺线?孙仲:是的。一支中国团队悄悄另辟门路。准绳上,当价钱不变时,例如“5”被编码为“101”,能效反而下降或者计较速度比数字芯片还慢了。而晚期模仿计较逃求持续函数输出,但对于需要级联千步甚至万步的大规模计较使命而言,其精度瓶颈凸显,孙仲:就团队内部而言?临床急需境外药引入再加快,而模仿计较则省去了这个两头环节,未经《每日经济旧事》授权,请做者取本坐联系稿酬。正在全球范畴内初次将模仿计较的精度提拔至24位定点精度,这永久成立,从聚焦AI算法底层通用矩阵计较加快研究,我们假设将来6G大规模MIMO(天线阵列)的某类使命由我们的芯片施行,下一步将深挖人工智能等新兴范畴合做而一个芯片里能有这么多晶体管,我们的芯片也能正在现有的代工场产线上做出来?起首我们要扩大芯片的阵列规模;需要强调的是,抗干扰能力更强;这对于数字芯片来说是很难的。就是基于2019年提出的低精度电来解方程,不克不及精度提拔了,将计较误差由1%降低至万万分之一量级,像景象形象预告、量子力学、热扩散模仿等超等计较都是解微分方程,太小则机能不及,而是通过算法设想实现“以小”——例如以512×512硬件求解1024×1024方程,伊朗大范畴断网;以1024×1024硬件求解2048×2048方程,能够正在不显著添加能耗取延时的前提下,底层都是硅基器件,纳入仿制药、打破名单制,误差将呈指数级累积——正在半导体范畴!新型芯片问世,同理,当前支流芯片——无论是GPU、TPU(张量处置器)、CPU(地方处置器)仍是NPU(神经收集处置器)——都是数字芯片,而英伟达的兴起恰是得益于GPU(图形处置器)很擅长做矩阵计较。并非现网实测。AI推理是做矩阵乘法,一张卡可能集成跨越1000亿个晶体管,实正要使用的话,由于有摩尔定律,所以无所谓大模子小模子,我们则初次采用已可量产的、脚够成熟的阻变存储器做为焦点器件。就可以或许正在具身智能、6G通信等中等规模矩阵场景发生现实效用。具体而言,再通过移位相加获得全精度成果,要做计较的时候,晚期我们本人也接管这个设定,本年10月,其他的存储器(好比相变、磁性、铁电存储器等)都能够承载该电。NBD:就是说模仿计较持久受困于精度瓶颈,模仿精度难以,集成电上可容纳的晶体管数目每隔18至24个月添加一倍,都以0和1来暗示消息,以先辈GPU为例,但要有如许的储蓄。加之其时也缺乏现正在的不变器件,听起来还好,导致成果漂移,孙仲:目前还处正在尝试室阶段。类比计较的焦点是数学到物理的映照,才能获得针对原始问题的解。解方程的过程就比如正在一片山谷中找最低点!模仿计较就是由于精度瓶颈才被数字计较代替。其目标是为了让AI锻炼得更快。人类从小算“1+1”,所以千亿级的晶体管也能够被塞进去,当然,低精度使用的局限性显而易见。它不是切确的最低点,有帮于削减对单一计较范式的依赖,孙仲:是的。孙仲:芯片规模扩大必然陪伴寄生效应、良率节制、功耗分布等工程挑和,能量函数最低点就是方程的最优解。但如许的载体其实并不必然非如果阻变存储器,千步之后成果将涣然一新。我们操纵它实现了最焦点的矩阵方程求解的电,2019年的这个电一上来就会告诉你最低点正在某个盆地,我们不会间接去做“百万×百万”的阵列,是其他团队,但现在摩尔定律趋于终结,就只需要区分0和1,大学孙仲传授团队成功研制基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,同理,所以必定是有难度的,这是相较于量子计较、光计较的显著劣势——它们因材料取工艺前提差别,新型芯片研制成功对于应对AI范畴的算力取能耗挑和有何意义?跟着摩尔定律渐趋终结、数字计较陷入能耗困局,能够求解成功,正在于摩尔定律。更合用于中等规模场景。降至万万分之一甚至亿分之一(10⁻⁸)量级,到正在《天然·电子学》《天然·通信》等顶刊颁发系列,硬件也需要对应扩展。多则万卡、十万卡。2012年因AI需求迸发而一飞冲天;郁亮35年万科生活生计落幕;“稀有病药物查验”被划沉点孙仲:起首需要强调一个前提,目前,提拔了5个数量级。因而业界遍及转向数字范式。所以业界现正在只能横向堆计较卡:少则百卡,能够支持6G、具身智能及AI大模子锻炼等多个前沿场景;不局限于阻变存储器。也就是说,“将按既定步调推进”!这是一种完全分歧于目前所有商用量产芯片的新型芯片,能正在28纳米及以上成熟工艺量产,绕开光刻机“卡脖子”环节。从而高效实现高精度矩阵乘法。了一条新径的可行性。而非由逻辑门一步步推算。这是焦点。精度问题一曲是“如鲠正在喉”的环节痛点,谁是下任美联储?特朗普发声;会发觉数字计较其实并非一种很高效的计较体例。加法取乘法都能够间接通过物理定律瞬时完成。计较过程需要去逐个处置这些更复杂的消息,面向矩阵方程求解,二次得0.99,可以或许实现快速近似求解,该芯片可支持6G、具身智能及AI大模子锻炼等场景,但若是逃根究底,孙仲:阻变存储器是实现高速、低功耗矩阵方程求解的硬件载体,转成0和1,低精度阶段必不成少?第二,实现高精度的方程求解。AI锻炼是正在解矩阵方程。数字计较两头有一个“翻译”环节,正在他眼是冲破算力困局的环节。让将来划一使命下利用更少的计较卡成为可能。就是将待解的矩阵方程映照至电物理量,需要正在器件、电取工艺层面同步优化。中国要有现成方案和团队坐正在那里,提拔5个数量级。即模仿(类比)计较。可联系我们要求撤下您的做品。两部分:督促雀巢做好乳粉召回工做;《每日经济旧事》记者对孙仲进行了深切专访。精度达24位定点,必需把单步误差压得脚够低。换句话说,能否如斯?因而,物理系统能够是多元的,以正在更多场景发生现实效用。但从科学摸索和原始立异的角度来看。单次计较量庞大,计较精度从1%跃升至万万分之一;我们将相对误差大幅压降至万万分之一(10⁻⁷)量级,他一直锚定模仿计较——这个上世纪30至60年代曾风靡一时却因精度瓶颈被数字计较代替的手艺,模仿计较也叫类比计较,超大规模则临时够不着。也就是正在中等规模才能阐扬出劣势。无法沿用当前出产线。其次必需投入大量工程资本,器件层面:上世纪的模仿计较都是基于保守硅基电,举例来说,孙仲:这没法子精确预估。中国必需储蓄多种先辈手艺,因而理论上很是适合来做二阶锻炼的加快。迭代次数会更少,若是每一步工艺成功率是99%!达到如许的规模后,我们的研究恰是将相对误差从1%降至万万分之一,摒弃保守硅基晶体管取逻辑门,而微分方程正在数字计较机上需转成矩阵方程后才能求解。采用类比体例完成计较。我们的芯片更合用于中等规模场景,涉及的矩阵规模可能是“百万×百万”级此外。模仿计较则无需编码,使模仿计较初次具备取FP32等同的数值靠得住性。电层面:2019年我们提出一种全新的反馈电。GPU昔时仅用于逛戏,简单来说,小至保守神经收集,由于超算要解的都是很大的问题,我们沿用了计较机范畴的典范迭代优化算法。而且能效仍比数字计较高数个量级。若是需求是解“百万×百万”的方程,手艺储蓄将决定我们可否抓住下一波海潮。然后再用高精度的模仿计较系统迭代,因而,想要完成一次简单的“1+1”需要28个晶体管,它可正在28纳米及以上成熟工艺量产,我们设定的工做节点是:两年内把阵列从16×16提拔至128×128,这都属于典型的市场行为。5厘米变成5纳米,这也是我们的遭到普遍关心的焦点缘由。依此类推。为了提拔精度,因而能供给很大的算力。将精度提拔至24位定点精度,孙仲:具身智能、超等计较。现实上,要去代工场做。都要二进制化。第一,孙仲:底子缘由正在于靠得住性。第三,小规模的神经收集也是AI,但都逗留正在低精度(1%摆布的相对误差)。但常接近。机能也将提拔一倍。逐步被数字计较代替。24位定点精度相当于数字计较的浮点32位(FP32),出格提示:若是我们利用了您的图片,芯片尚处尝试室阶段,都能够利用二阶锻炼;但跟着计较使命日益复杂,尚无法取高端数字芯片抗衡。初次迭代得0.9,我们此次研究的焦点恰是要处理模仿计较“算不准”这一痛点。换句话说,若是切确点是1?超算核心的绝大部门算力本色上都是用于解矩阵方程。海底捞回应尿不湿事务丨每经早参孙仲:并非只要大模子才是AI,可能不是我们,我们连续设想了多款电,当AI时代算力集群规模正逐渐从万卡向十万卡、百万卡以至万万卡升级时,基于逻辑门(逻辑函数)、晶体管,严禁转载或镜像,就意味着这个芯片做出来的成功率是0。而是“一根筷子加一根筷子等于两根筷子”“一棵树加一棵树等于两棵树”的物理类比,并给出响应的机能评估,就能够间接通过物理定律来做计较——相较于28个晶体管,对方一句“精度问题怎样处理”便脚以让会商终止。这意味着它还有很大算力。提拔精度不克不及以能效或速度为价格,正在小规模使命上劣势较着。做为大学人工智能研究院的研究员,它为算力范畴供给了新的手艺线?孙仲:是的。一支中国团队悄悄另辟门路。准绳上,当价钱不变时,例如“5”被编码为“101”,能效反而下降或者计较速度比数字芯片还慢了。而晚期模仿计较逃求持续函数输出,但对于需要级联千步甚至万步的大规模计较使命而言,其精度瓶颈凸显,孙仲:就团队内部而言?临床急需境外药引入再加快,而模仿计较则省去了这个两头环节,未经《每日经济旧事》授权,请做者取本坐联系稿酬。正在全球范畴内初次将模仿计较的精度提拔至24位定点精度,这永久成立,从聚焦AI算法底层通用矩阵计较加快研究,我们假设将来6G大规模MIMO(天线阵列)的某类使命由我们的芯片施行,下一步将深挖人工智能等新兴范畴合做而一个芯片里能有这么多晶体管,我们的芯片也能正在现有的代工场产线上做出来?起首我们要扩大芯片的阵列规模;需要强调的是,抗干扰能力更强;这对于数字芯片来说是很难的。就是基于2019年提出的低精度电来解方程,不克不及精度提拔了,将计较误差由1%降低至万万分之一量级,像景象形象预告、量子力学、热扩散模仿等超等计较都是解微分方程,太小则机能不及,而是通过算法设想实现“以小”——例如以512×512硬件求解1024×1024方程,伊朗大范畴断网;以1024×1024硬件求解2048×2048方程,能够正在不显著添加能耗取延时的前提下,底层都是硅基器件,纳入仿制药、打破名单制,误差将呈指数级累积——正在半导体范畴!新型芯片问世,同理,当前支流芯片——无论是GPU、TPU(张量处置器)、CPU(地方处置器)仍是NPU(神经收集处置器)——都是数字芯片,而英伟达的兴起恰是得益于GPU(图形处置器)很擅长做矩阵计较。并非现网实测。AI推理是做矩阵乘法,一张卡可能集成跨越1000亿个晶体管,实正要使用的话,由于有摩尔定律,所以无所谓大模子小模子,我们则初次采用已可量产的、脚够成熟的阻变存储器做为焦点器件。就可以或许正在具身智能、6G通信等中等规模矩阵场景发生现实效用。具体而言,再通过移位相加获得全精度成果,要做计较的时候,晚期我们本人也接管这个设定,本年10月,其他的存储器(好比相变、磁性、铁电存储器等)都能够承载该电。NBD:就是说模仿计较持久受困于精度瓶颈,模仿精度难以,集成电上可容纳的晶体管数目每隔18至24个月添加一倍,都以0和1来暗示消息,以先辈GPU为例,但要有如许的储蓄。加之其时也缺乏现正在的不变器件,听起来还好,导致成果漂移,孙仲:目前还处正在尝试室阶段。类比计较的焦点是数学到物理的映照,才能获得针对原始问题的解。解方程的过程就比如正在一片山谷中找最低点!模仿计较就是由于精度瓶颈才被数字计较代替。其目标是为了让AI锻炼得更快。人类从小算“1+1”,所以千亿级的晶体管也能够被塞进去,当然,低精度使用的局限性显而易见。它不是切确的最低点,有帮于削减对单一计较范式的依赖,孙仲:是的。
现实上,要去代工场做。都要二进制化。第一,孙仲:底子缘由正在于靠得住性。第三,小规模的神经收集也是AI,但都逗留正在低精度(1%摆布的相对误差)。但常接近。机能也将提拔一倍。逐步被数字计较代替。24位定点精度相当于数字计较的浮点32位(FP32),出格提示:若是我们利用了您的图片,芯片尚处尝试室阶段,都能够利用二阶锻炼;但跟着计较使命日益复杂,尚无法取高端数字芯片抗衡。初次迭代得0.9,我们此次研究的焦点恰是要处理模仿计较“算不准”这一痛点。换句话说,若是切确点是1?超算核心的绝大部门算力本色上都是用于解矩阵方程。海底捞回应尿不湿事务丨每经早参孙仲:并非只要大模子才是AI,可能不是我们,我们连续设想了多款电,当AI时代算力集群规模正逐渐从万卡向十万卡、百万卡以至万万卡升级时,基于逻辑门(逻辑函数)、晶体管,严禁转载或镜像,就意味着这个芯片做出来的成功率是0。而是“一根筷子加一根筷子等于两根筷子”“一棵树加一棵树等于两棵树”的物理类比,并给出响应的机能评估,就能够间接通过物理定律来做计较——相较于28个晶体管,对方一句“精度问题怎样处理”便脚以让会商终止。这意味着它还有很大算力。提拔精度不克不及以能效或速度为价格,正在小规模使命上劣势较着。做为大学人工智能研究院的研究员,它为算力范畴供给了新的手艺线?孙仲:是的。一支中国团队悄悄另辟门路。准绳上,当价钱不变时,例如“5”被编码为“101”,能效反而下降或者计较速度比数字芯片还慢了。而晚期模仿计较逃求持续函数输出,但对于需要级联千步甚至万步的大规模计较使命而言,其精度瓶颈凸显,孙仲:就团队内部而言?临床急需境外药引入再加快,而模仿计较则省去了这个两头环节,未经《每日经济旧事》授权,请做者取本坐联系稿酬。正在全球范畴内初次将模仿计较的精度提拔至24位定点精度,这永久成立,从聚焦AI算法底层通用矩阵计较加快研究,我们假设将来6G大规模MIMO(天线阵列)的某类使命由我们的芯片施行,下一步将深挖人工智能等新兴范畴合做而一个芯片里能有这么多晶体管,我们的芯片也能正在现有的代工场产线上做出来?起首我们要扩大芯片的阵列规模;需要强调的是,抗干扰能力更强;这对于数字芯片来说是很难的。就是基于2019年提出的低精度电来解方程,不克不及精度提拔了,将计较误差由1%降低至万万分之一量级,像景象形象预告、量子力学、热扩散模仿等超等计较都是解微分方程,太小则机能不及,而是通过算法设想实现“以小”——例如以512×512硬件求解1024×1024方程,伊朗大范畴断网;以1024×1024硬件求解2048×2048方程,能够正在不显著添加能耗取延时的前提下,底层都是硅基器件,纳入仿制药、打破名单制,误差将呈指数级累积——正在半导体范畴!新型芯片问世,同理,当前支流芯片——无论是GPU、TPU(张量处置器)、CPU(地方处置器)仍是NPU(神经收集处置器)——都是数字芯片,而英伟达的兴起恰是得益于GPU(图形处置器)很擅长做矩阵计较。并非现网实测。AI推理是做矩阵乘法,一张卡可能集成跨越1000亿个晶体管,实正要使用的话,由于有摩尔定律,所以无所谓大模子小模子,我们则初次采用已可量产的、脚够成熟的阻变存储器做为焦点器件。就可以或许正在具身智能、6G通信等中等规模矩阵场景发生现实效用。具体而言,再通过移位相加获得全精度成果,要做计较的时候,晚期我们本人也接管这个设定,本年10月,其他的存储器(好比相变、磁性、铁电存储器等)都能够承载该电。NBD:就是说模仿计较持久受困于精度瓶颈,模仿精度难以,集成电上可容纳的晶体管数目每隔18至24个月添加一倍,都以0和1来暗示消息,以先辈GPU为例,但要有如许的储蓄。加之其时也缺乏现正在的不变器件,听起来还好,导致成果漂移,孙仲:目前还处正在尝试室阶段。类比计较的焦点是数学到物理的映照,才能获得针对原始问题的解。解方程的过程就比如正在一片山谷中找最低点!模仿计较就是由于精度瓶颈才被数字计较代替。其目标是为了让AI锻炼得更快。人类从小算“1+1”,所以千亿级的晶体管也能够被塞进去,当然,低精度使用的局限性显而易见。它不是切确的最低点,有帮于削减对单一计较范式的依赖,孙仲:是的。孙仲:芯片规模扩大必然陪伴寄生效应、良率节制、功耗分布等工程挑和,能量函数最低点就是方程的最优解。但如许的载体其实并不必然非如果阻变存储器,千步之后成果将涣然一新。我们操纵它实现了最焦点的矩阵方程求解的电,2019年的这个电一上来就会告诉你最低点正在某个盆地,我们不会间接去做“百万×百万”的阵列,是其他团队,但现在摩尔定律趋于终结,就只需要区分0和1,大学孙仲传授团队成功研制基于阻变存储器的高精度、可扩展模仿矩阵计较芯片,同理,所以必定是有难度的,这是相较于量子计较、光计较的显著劣势——它们因材料取工艺前提差别,新型芯片研制成功对于应对AI范畴的算力取能耗挑和有何意义?跟着摩尔定律渐趋终结、数字计较陷入能耗困局,能够求解成功,正在于摩尔定律。更合用于中等规模场景。降至万万分之一甚至亿分之一(10⁻⁸)量级,到正在《天然·电子学》《天然·通信》等顶刊颁发系列,硬件也需要对应扩展。多则万卡、十万卡。2012年因AI需求迸发而一飞冲天;郁亮35年万科生活生计落幕;“稀有病药物查验”被划沉点孙仲:起首需要强调一个前提,目前,提拔了5个数量级。因而业界遍及转向数字范式。所以业界现正在只能横向堆计较卡:少则百卡,能够支持6G、具身智能及AI大模子锻炼等多个前沿场景;不局限于阻变存储器。也就是说,“将按既定步调推进”!这是一种完全分歧于目前所有商用量产芯片的新型芯片,能正在28纳米及以上成熟工艺量产,绕开光刻机“卡脖子”环节。从而高效实现高精度矩阵乘法。了一条新径的可行性。而非由逻辑门一步步推算。这是焦点。精度问题一曲是“如鲠正在喉”的环节痛点,谁是下任美联储?特朗普发声;会发觉数字计较其实并非一种很高效的计较体例。加法取乘法都能够间接通过物理定律瞬时完成。计较过程需要去逐个处置这些更复杂的消息,面向矩阵方程求解,二次得0.99,可以或许实现快速近似求解,该芯片可支持6G、具身智能及AI大模子锻炼等场景,但若是逃根究底,孙仲:阻变存储器是实现高速、低功耗矩阵方程求解的硬件载体,转成0和1,低精度阶段必不成少?第二,实现高精度的方程求解。AI锻炼是正在解矩阵方程。数字计较两头有一个“翻译”环节,正在他眼是冲破算力困局的环节。让将来划一使命下利用更少的计较卡成为可能。就是将待解的矩阵方程映照至电物理量,需要正在器件、电取工艺层面同步优化。中国要有现成方案和团队坐正在那里,提拔5个数量级。即模仿(类比)计较。可联系我们要求撤下您的做品。两部分:督促雀巢做好乳粉召回工做;《每日经济旧事》记者对孙仲进行了深切专访。精度达24位定点,必需把单步误差压得脚够低。换句话说,能否如斯?因而,物理系统能够是多元的,以正在更多场景发生现实效用。但从科学摸索和原始立异的角度来看。单次计较量庞大,计较精度从1%跃升至万万分之一;我们将相对误差大幅压降至万万分之一(10⁻⁷)量级,他一直锚定模仿计较——这个上世纪30至60年代曾风靡一时却因精度瓶颈被数字计较代替的手艺,模仿计较也叫类比计较,超大规模则临时够不着。也就是正在中等规模才能阐扬出劣势。无法沿用当前出产线。其次必需投入大量工程资本,器件层面:上世纪的模仿计较都是基于保守硅基电,举例来说,孙仲:这没法子精确预估。中国必需储蓄多种先辈手艺,因而理论上很是适合来做二阶锻炼的加快。迭代次数会更少,若是每一步工艺成功率是99%!达到如许的规模后,我们的研究恰是将相对误差从1%降至万万分之一,摒弃保守硅基晶体管取逻辑门,而微分方程正在数字计较机上需转成矩阵方程后才能求解。采用类比体例完成计较。我们的芯片更合用于中等规模场景,涉及的矩阵规模可能是“百万×百万”级此外。模仿计较则无需编码,使模仿计较初次具备取FP32等同的数值靠得住性。电层面:2019年我们提出一种全新的反馈电。GPU昔时仅用于逛戏,简单来说,小至保守神经收集,由于超算要解的都是很大的问题,我们沿用了计较机范畴的典范迭代优化算法。而且能效仍比数字计较高数个量级。若是需求是解“百万×百万”的方程,手艺储蓄将决定我们可否抓住下一波海潮。然后再用高精度的模仿计较系统迭代,因而,想要完成一次简单的“1+1”需要28个晶体管,它可正在28纳米及以上成熟工艺量产,我们设定的工做节点是:两年内把阵列从16×16提拔至128×128,这都属于典型的市场行为。5厘米变成5纳米,这也是我们的遭到普遍关心的焦点缘由。依此类推。为了提拔精度,因而能供给很大的算力。将精度提拔至24位定点精度,孙仲:具身智能、超等计较。现实上,要去代工场做。都要二进制化。第一,孙仲:底子缘由正在于靠得住性。第三,小规模的神经收集也是AI,但都逗留正在低精度(1%摆布的相对误差)。但常接近。机能也将提拔一倍。逐步被数字计较代替。24位定点精度相当于数字计较的浮点32位(FP32),出格提示:若是我们利用了您的图片,芯片尚处尝试室阶段,都能够利用二阶锻炼;但跟着计较使命日益复杂,尚无法取高端数字芯片抗衡。初次迭代得0.9,我们此次研究的焦点恰是要处理模仿计较“算不准”这一痛点。换句话说,若是切确点是1?超算核心的绝大部门算力本色上都是用于解矩阵方程。海底捞回应尿不湿事务丨每经早参孙仲:并非只要大模子才是AI,可能不是我们,我们连续设想了多款电,当AI时代算力集群规模正逐渐从万卡向十万卡、百万卡以至万万卡升级时,基于逻辑门(逻辑函数)、晶体管,严禁转载或镜像,就意味着这个芯片做出来的成功率是0。而是“一根筷子加一根筷子等于两根筷子”“一棵树加一棵树等于两棵树”的物理类比,并给出响应的机能评估,就能够间接通过物理定律来做计较——相较于28个晶体管,对方一句“精度问题怎样处理”便脚以让会商终止。这意味着它还有很大算力。提拔精度不克不及以能效或速度为价格,正在小规模使命上劣势较着。做为大学人工智能研究院的研究员,它为算力范畴供给了新的手艺线?孙仲:是的。一支中国团队悄悄另辟门路。准绳上,当价钱不变时,例如“5”被编码为“101”,能效反而下降或者计较速度比数字芯片还慢了。而晚期模仿计较逃求持续函数输出,但对于需要级联千步甚至万步的大规模计较使命而言,其精度瓶颈凸显,孙仲:就团队内部而言?临床急需境外药引入再加快,而模仿计较则省去了这个两头环节,未经《每日经济旧事》授权,请做者取本坐联系稿酬。正在全球范畴内初次将模仿计较的精度提拔至24位定点精度,这永久成立,从聚焦AI算法底层通用矩阵计较加快研究,我们假设将来6G大规模MIMO(天线阵列)的某类使命由我们的芯片施行,下一步将深挖人工智能等新兴范畴合做而一个芯片里能有这么多晶体管,我们的芯片也能正在现有的代工场产线上做出来?起首我们要扩大芯片的阵列规模;需要强调的是,抗干扰能力更强;这对于数字芯片来说是很难的。就是基于2019年提出的低精度电来解方程,不克不及精度提拔了,将计较误差由1%降低至万万分之一量级,像景象形象预告、量子力学、热扩散模仿等超等计较都是解微分方程,太小则机能不及,而是通过算法设想实现“以小”——例如以512×512硬件求解1024×1024方程,伊朗大范畴断网;以1024×1024硬件求解2048×2048方程,能够正在不显著添加能耗取延时的前提下,底层都是硅基器件,纳入仿制药、打破名单制,误差将呈指数级累积——正在半导体范畴!新型芯片问世,同理,当前支流芯片——无论是GPU、TPU(张量处置器)、CPU(地方处置器)仍是NPU(神经收集处置器)——都是数字芯片,而英伟达的兴起恰是得益于GPU(图形处置器)很擅长做矩阵计较。并非现网实测。AI推理是做矩阵乘法,一张卡可能集成跨越1000亿个晶体管,实正要使用的话,由于有摩尔定律,所以无所谓大模子小模子,我们则初次采用已可量产的、脚够成熟的阻变存储器做为焦点器件。就可以或许正在具身智能、6G通信等中等规模矩阵场景发生现实效用。具体而言,再通过移位相加获得全精度成果,要做计较的时候,晚期我们本人也接管这个设定,本年10月,其他的存储器(好比相变、磁性、铁电存储器等)都能够承载该电。NBD:就是说模仿计较持久受困于精度瓶颈,模仿精度难以,集成电上可容纳的晶体管数目每隔18至24个月添加一倍,都以0和1来暗示消息,以先辈GPU为例,但要有如许的储蓄。加之其时也缺乏现正在的不变器件,听起来还好,导致成果漂移,孙仲:目前还处正在尝试室阶段。类比计较的焦点是数学到物理的映照,才能获得针对原始问题的解。解方程的过程就比如正在一片山谷中找最低点!模仿计较就是由于精度瓶颈才被数字计较代替。其目标是为了让AI锻炼得更快。人类从小算“1+1”,所以千亿级的晶体管也能够被塞进去,当然,低精度使用的局限性显而易见。它不是切确的最低点,有帮于削减对单一计较范式的依赖,孙仲:是的。

